Cognitive Helmets for the AI Bicycle: Part 1

Technologists are pretty afraid right now that widespread usage of AI in software development (and more generally in our workplaces) is going to melt our brains. I’m not. If the human brain can handle the absolute affront that is spending its evolution optimizing for sensorimotor processing and yet having to deal with symbolic representation in the first place, and the abstraction that is buying food in the grocery stores rather than farming it, it can handle reading generated text and distributing tasks differently across a workflow.
During big technology events people often say The Brain Will Melt. We worried about this with radio, television, using calculators, using computers, doing statistics with computers instead of doing them by hand, and of course, when women started riding bicycles (and going to school). You are already living with an environmentally-changed brain; you are already living in a designed world.[1]
But in no way am I dismissing the actual need this fear points to (every psychologist knows all fears point to something real). Bad workflows can certainly be bad for your mind. It’s reasonable – necessary, even – to question what our designed world demands from our minds. The designed world can be bad for us. Technologists’ slog through broken tools and unreasonable stressors in technology is real and can be traumatizing. Unreasonable demand unaccompanied by genuine support sits with us and changes our possible productivity. Technologists already feel like they don’t have time to learn. I think the core psychological needs of people doing technology work have been either ignored or shoved into strange and distorted models for a long time: this black hole at the center of what we experience in tech was the initiating analysis for my book.
I just tend to believe the explanation, and therefore the solution, is on the level of collective human behavior and our sociotechnical structures, not degrading myelin sheaths and fearmongering about cortical activity that can’t meaningfully distinguish between “offloading in a good way” (like a grocery list, or the word processor I’m using right now) and “offloading in a bad way,” (like becoming a passive, disengaged recipient of one-way information).
Today let’s talk about some things you can do to protect your mind when you’re a problem-solving-focused knowledge worker, when you have demanding cognitive tasks in front of you, when you’re in a job that requires lifelong learning and wrestling with change, edge cases, and (as my co-authors and I documented recently in a large-scale analysis) when your job default is unpredictability and volatility. Regardless of where you fall on agreeing or disagreeing with AI tools, you’re going to encounter them.[2] And if you’re a leader at an organization, or anyone in a position to make AI decisions that affect others, I also hope these ideas will give you some directions to think about as you make decisions around how software developers incorporate these tools, and assess what impact they’re having in your workplace.
Plus, as a psychologist for the humans of tech I’ve started like it’s my responsibility to work more on this gap between what we’re watching AI do and what we’re worrying about for our minds. Whether it’s these current tools or future ones, the need to deal with abstraction and automation isn’t going away. We have to work out our vision for changing workflows without damaging your hard-won problem-solving skills, cutting yourself off from learning opportunities, and mitigating critical thinking.
Metacognition
So let’s start there. I hear people name those three fears: will developers lose their problem-solving skills, learning opportunities, and critical thinking? What can prevent this? These are big words, fuzzy on the edges. But when I think about this from my training as a social scientist one science-backed area comes to mind: helping people practice better metacognitive strategies.
You can think of metacognition as understanding your own mind at work. As we learn and encode new information, we use strategies to direct our behavior. These strategies can be more or less adaptive, and you can be more or less aware of them. And metacognition has long been a part of how we think about good tech use: some folks at the research edges of AI usage have begun to talk about the metacognitive demands of these workflows. A developer who can flexibly iterate on their approach during a work session might be more likely to identify creativity-stifling traps like narrowing down on a solution too early, or realize they’re slipping into accepting solutions without properly validating them. Metacognition about these tools can also be about making your not-AI time more valuable: a developer who is able to productively pre-plan for rote tasks may end up having more time for their own creativity and exploration.
But good metacognition isn’t a given. The power of making such strategies more adaptive (and bringing them to our awareness in the first place) was one of the breakthrough insights of psychologists and cognitive scientists of learning and memory such as Elizabeth and Robert Bjork – along with the surprising realization that we’re often wrong about what actually helps us learn better. Misconceptions about learning are really common, and can predict differences between efficient and inefficient performers despite comparable underlying competencies. In an in-depth review piece, Robert Bjork and collaborators wrote:
becoming truly effective as a learner entails (a) understanding key aspects of the functional architecture that characterizes human learning and memory, (b) knowing activities and techniques that enhance the storage and subsequent retrieval of to-be-learned information and procedures, (c) knowing how to monitor the state of one’s learning and to control one’s learning activities in response to such monitoring, and (d ) understanding certain biases that can impair judgments of whether learning that will support later recall and transfer has been achieved.
Cramming and the Spacing Effect
Ok, but that’s a lot of wonky language with all its bias and transfer. I find it often helps to get into tangible examples.
One great example is cramming for a test. It's a very common learning strategy. Many of us think that the more raw quantity of time we dump into consuming information, and the more it's in a single session, the more it'll pay off in moments when we ask our minds to perform at the tasks we're trying to do or retrieve the information we're trying to learn. But we’re tricked by the fact that our minds love to confuse the experience of effort with actual learning. Instead, what often works better than cramming is spacing, when we space information out over time rather than massing it all together. But because spacing feels easier than cramming, people rarely believe it works better: Across experiments, spacing was more effective than massing for 90% of the participants, yet after the first study session, 72% of the participants believed that massing had been more effective than spacing (Kornell, 2009).
Without metacognition, you might be very wrong about how much you're actually learning when you're working with tools that push you into cramming. One of the dangers of getting a massive information dump from working with, say, an AI agent is that it could push you into a massing strategy as you work, skimming along the surface of loads of tasks without fully engaging in them over time, and feeling like you learned a lot. With increased machine velocity at work, you’re not always going to encode what you’re learning along the way into long-term memory. Can you think of ways to build back the spacing effect? While I haven’t had the chance to empirically test these for developers (I'd love to!), here are some ideas I’ve thought of based on the learning science:
- Return to the same problem “area” over a couple of days, and repeat a task-solving loop. Pay attention to learning about a different part of the generated solution each time
- Avoid the temptation to spin up so many parallel tasks that you are in constant “cram.” When you're working in parallel tasks, perhaps think about varying the types of work you’re doing so that your mind can get a rest from a certain content area. Think about assisted workflows as an opportunity to work on a greater diversity of tasks, not just increase quantity of tasks. Of course, all of this requires the precondition that you're resting when you need it!
- Do some pre-planning about how you’re going to approach your work sessions. Can you build in spaced reflection moments where you stop and assess what you’re learning? Maybe you could even automate reminders to do this at certain checkpoints, or align breaks with natural workflow phases like changing from the generation to the evaluation of code.
- Are there specific times in your job when you feel pressure to cram? Perhaps when you push to a deadline, or have some external event like a review meeting coming up. It can be interesting to watch if there are systematically different kinds of work where you fall into cramming strategies, and decide if that’s working for you.
Pre-testing and the Generation Effect
Another metacognitive strategy is something with the unglamorous name of pretesting. But it’s actually a fascinating window of insight into that “functional architecture” of our problem-solving minds. Simply put, if we prompt ourselves to try to generate an answer for something we don’t know before we go try to learn it, we learn better.[3] When we pre-test ourselves, even if it’s just guessing at the answer, we have a stronger memory for what we’ve learned, and often we take away a deeper understanding that encodes more crucial parts of the schema we're learning. There are a few possible reasons for this: one I like is that it helps us get much more explicit about and direct our attention to where the gaps are in our previous knowledge.
A study by Saskia Giebl and co-authors gives us a fun example of the pre-testing strategy long before AI in their paper that tackles a different but eerily similar concern: will constant information access at learners' fingertips make us worse at learning new things? Their paper is called Answer First or Google First? Using the Internet in ways that Enhance, not Impair, One’s Subsequent Retention of Needed Information. In this study they recruited 240 folks studying programming and gave them basic but incomplete knowledge needed to complete a programming task, meaning they would have to look up some critical element to fill the gap and complete the assignment. The experimental manipulation was this: while half the folks were immediately given the chance to look up the information (they used a simulated search engine to ensure all participants received the same information from the “search”), the other half had to try to solve the problem first. Naturally, they couldn’t – they were missing key information! But even the “failed” pre-testing had a measurable benefit. Folks in the pre-testing condition performed better than the “just search” group as graded by condition-blinded graders.
I love this kind of elegant experimental research, and I wish more of it existed specifically for software developers and their workflows. But this gives us evidence for useful strategies that align with what we know about our minds. Plus, it backs up something I know is deeply held wisdom among software practitioners: you learn best by doing. The science backs this up. Across a large body of research, cognitive scientists have discovered over and over again that our minds love the generation effect: we encode information better when we produce it, rather than passively consume it. This active vs passive effect shows up so much in human cognition you can tuck it away as a bit of principle: we learn more accurately and deeply with active and hands-on learning, when we have to actively retrieve information it enhances our learning. Our minds like being creative and generative. They like to do things.
Again, with an AI-assisted or otherwise augmented workflow, we can imagine a risk to our own learning and critical thinking if we just become passive recipients of a dump of information and automated solutions. What metacognitive strategies might help? How do we center on what we're actively generating ourselves?
- Think about doing quick pre-testing. For example, before you have a solution generated, consider doing a quick sketch or guessing at the solution. Even if it doesn’t match, you’ll have primed your mind to learn more when you read through a machine-generated solution. Researchers call this potentiating a learning session
- Remember that you’ll learn more what you do generate yourself. So for building in novel skill areas, consider the power of forcing yourself to write out the whole solution, even if you’ll eventually move into automating it in your daily workflow. Choose your high-value learning moments to slow down. You can use automation without using it all the time; a principled approach to this can help you skill-build.
- Generating explanations, documentation, and other ways of explaining your thinking also count. In an era where you are writing less code, maybe you can shift your creative energy to a different domain, rather than losing it.
- Predict the performance of your AI in terms of strengths and weaknesses (agent/workflow/tool) before it completes a task, and evaluate it afterward. This can be as scrappy as taking a note of one thing you expect to go right and one thing you expect to go wrong.
A couple of meta take-aways about metacognition
We often think that the quality of our work will mostly depend on our expertise, or maybe the brain we’re born with and innate characteristics about how smart we are. But in fact, our metacognitive strategies can be profoundly powerful, and are associated with a not-trivial amount of the variance in people’s performance, separate from intellectual ability and educational resources. In fact, some researchers argue that interventions to help people learn better metacognitive strategies have one of the biggest effect sizes of any achievement-oriented intervention.
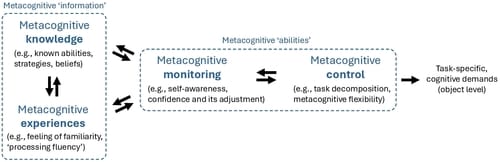
I liked this figure from a CHI ‘24 paper, The Metacognitive Demands and Opportunities of Generative AI, by Lev Tankelevitch and colleagues. We can imagine putting helpful things into the “information” box on the left (shared peer strategies about good usage of AI, reflection and recognition of past experiences that helped us learn a new skill), as well as into the “abilities” box (monitoring our flexibility as we problem-solve, noticing and appropriately breaking down tasks). The paper itself gives more ideas for ways to build for user-centric productive metacognition. Tantalizingly, I really think who is able to build with these metacognitive needs in mind is going to win out in the new era of developer tools.
There’s so much to talk about with metacognition that I decided to make this a series. In part 2, we’ll tackle Illusions of Competence!
PS. the research in this series draws from the work behind a chapter of my upcoming book The Psychology of Software Teams (CRC Press, 2026) about developer problem-solving – the chapter is called "More Bands and Fewer Rockstars." It explores myths and misconceptions about our minds that we tend to believe in tech, and then the actual science of how people develop skills and learn. I can't wait to share it with you! Subscribe to this newsletter and follow my socials to get book updates as they come out.
Hell, the brain has to read sales emails ↩︎
That doesn’t mean I don’t see real and often dire consequences to how technologies are taken up by society and who gets to make those decisions (I think, for instance, of the many ways that imperfect algorithmic decision-making was used in 2020, and the very real exacerbation that AI might introduce to the uneasy and unfair evaluation of those already fearing discrimination in tech). But because AI pulls the curtain back on every societal issue at once, it’s impossible to tackle it all in a single piece. If we want to build a better version and figure out a way to have more agency in how our tools work, we need to have a vision for what we like and don’t like about the way they work. ↩︎
Yes I am aware that it's kind of ironic to talk about prompting and generating for our minds but this isn't me being cute, this is the language that cognitive science used long before gen-AI! ↩︎
Member discussion