Are developers slowed down by AI? Evaluating an RCT (?) and what it tells us about developer productivity

Seven different people texted or otherwise messaged me about this study which claims to measure “the impact of early-2025 AI on experienced open-source developer productivity.”
You know, when I decided to become a psychological scientist I never imagined that “teaching research methods so we can actually evaluate evidence about developers” could ever graduate into a near fulltime beat but when the people call, I answer. Let’s talk about RCTs, evaluating claims made in papers vs by headlines, and causality.

The Study
This study leads with a plot that’s of course already been pulled into various press releases and taken on life on social media:
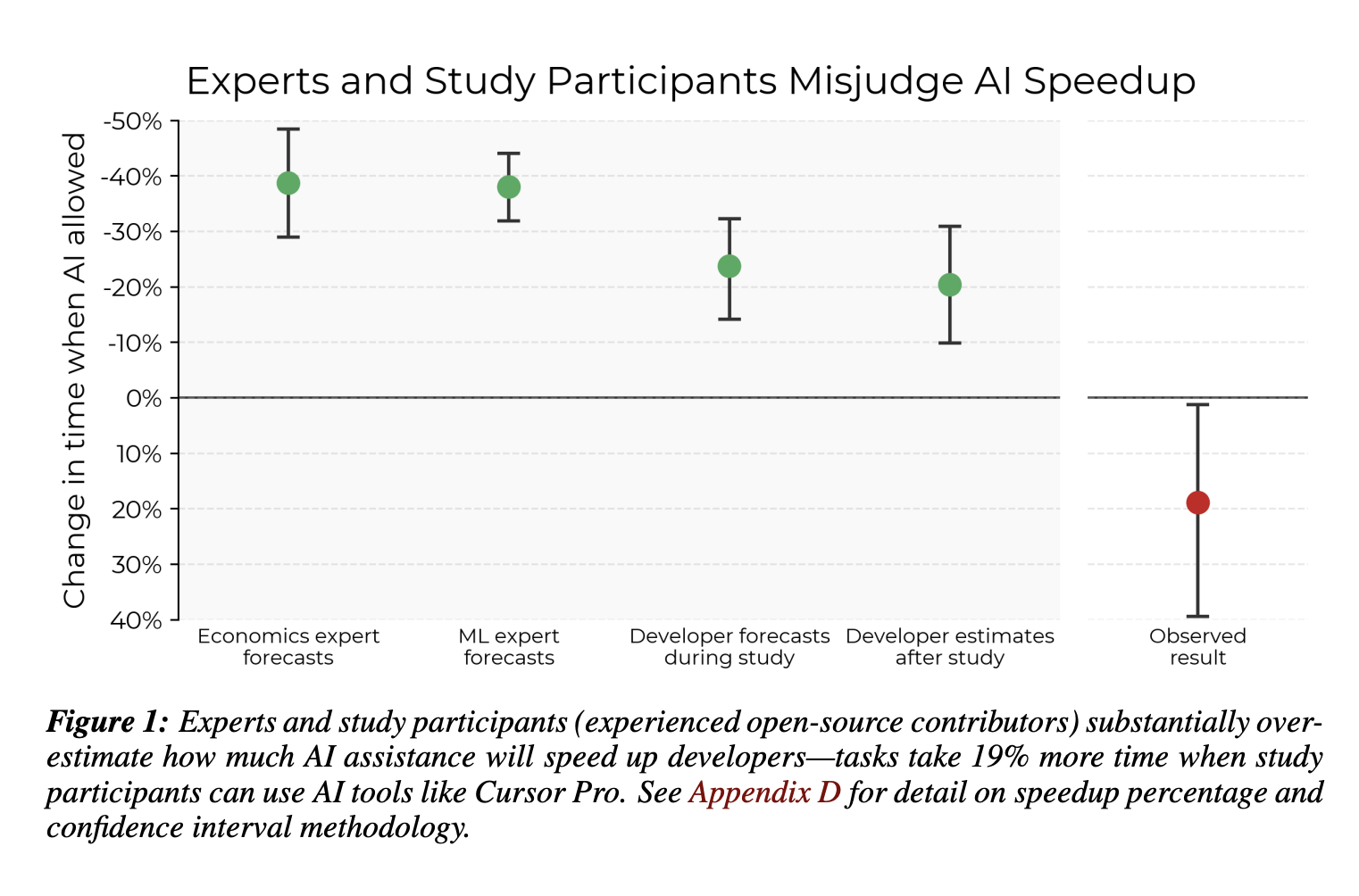
In brief, 16 open-source software developers were recruited to complete development tasks for this research project. They provided tasks themselves, out of real issues and work in their repository (I think this is one of the most interesting features). These tasks were then randomly assigned to either be in the “AI” (for a pretty fluid and unclear definition of AI because how AI was used was freely chosen) or “not AI” condition.
There are some important design details to consider:
- The randomization occurred on the level of the tasks not on the level of the people, which I’ve seen a number of folks confused by in the reactions to this paper. However, to me the randomization does not include standardization of treatment. The treatment can be quite variable depending on the task within the “AI condition.” This is probably why that caption says "can" use AI and not "using AI."
- The tasks were not standardized between developers but were instead situated, real issues that these recruited folks were working on in their own repositories. Therefore the tasks are not directly comparable to each other, although there is some amount of context of the tasks provided. This will be very important to remember.
- Repositories, then, is also a variable in this study that goes along with developer, because developers are working in a different project context and a different issue context. Presumably modeling developer with ‘AI/no AI’ within developer also includes repo and developers only worked in one repo. I just think it’s helpful to remember that the repo might include context that impacts across issues and changes the AI possibilities (e.g. a simple causal scenario: the same AI tool might fail at a task in one repo but be successful at it in another repo, caused by something about the structure of the repo).
- There is a ton of developer free choice in this design. Notably developers got to choose the order they worked on tasks. They even sometimes worked on multiple issues at a time!
- They could also dial up or down the amount of “AI” in the treatment condition, and what type of tool they used. When doing an “AI” assigned task, developers could use AI pretty much as much as they wanted or down to and including not at all in the “AI” condition.
- All developers got tasks in both conditions. This is what we call a within-subject design. This is also one reason that we have many observations in this study despite the N being low (small number of people, relatively larger number of tasks).
- Note that the intervals around the slowdown effect are large, while on the negative side, still quite close to overlapping 0%. It has also been pointed out that the original study missed designing the analysis correctly for repeated measures although an author has since come into that post to say the differences are not big when they do, so we will take their word for this. Either way, I will take some issue with treating this point estimate as a sweeping statement about developers’ time while working with AI.
- They also collect screen recordings, which aren’t much dwelled on here, and my guess is that a bigger project in the future will come out about this. They manually label 143 hours of recordings, which is impressive. That being said, it’s a bit opaque as to how the labeling categories are created and why they were the ones chosen. I find some of the overlap confusing in terms of categorizing the commonalities between AI and not-AI tasks in terms of the human activity involved, e.g., “reviewing AI output” could be considered a form of “reading”, and “Waiting on AI” sounds like the same thing as “Idle.” It is clear from G.8 that the labeling was done by contract and not by the authors themselves and it looks like the requirements are programming experience and Cursor experience, rather than behavioral science experience.
Study context: This preprint/report (I’m not entirely sure what to call it – it’s hosted on their website), is put out by METR, which appears to be a donation-funded org doing what they describe as “evaluations of frontier AI systems’ ability to complete complex tasks without human input.” They also list some partnerships with companies, including OpenAI. I have zero connection to or knowledge of this org or any of these folks, their website seems to provide some nice transparency. I have done plenty of research work that relies on funding within the industry, including running a lab at a tech company. I think donation-based organizations doing research are providing an interesting and important service. I strongly think that software teams need more research and that tech companies who profit so much from software work would benefit from funding research. These authors deserve credit for sharing an open access report with rich detail, including the scripts and instructions that participant saw, as that deeply helps us evaluate their claims.
On to the study!
I have thoughts about this study, and they’re overlapping, so I’ve tried to roughly organize these into categories but research design is a many-headed hydra kind of thing, just like software development, where one issue frequently bleeds into others.
Time, Forecasting, and Productivity?
The study makes a rather big thing of the time estimates and then the actual time measure in the AI allowed condition. Everyone is focusing on that Figure 1, but interestingly, devs’ forecasting about AI-allowed issues are just as or more correlated with actual completion time as their pre-estimates are for the AI-disallowed condition: .64 and .59 respectively. In other words despite their optimistic bias (in retrospect) about AI time savings being off which shifts their estimates, the AI condition doesn’t seem to have made developers more inaccurate in their pre-planning about ranking the relative effort the issue will take to solve out of a pool of issues.
I feel that this is a very strange counterpoint to the “AI drags down developers and they didn’t know it” take-away that is being framed as the headline. If we want to know if developers are accurate about predicting how long their work will take them when they use AI, well, it seems like the AI condition didn't make them any worse at ranking the issues, at least for complex work like software where it’s notoriously difficult to make a time estimate, although perhaps optimistically shifted. If we want to know on the other hand if “devs are kind of inaccurate when looking back at a bunch of tasks they finished with a new tool and being asked if the new tool helped,” well, they kind of are. But surely the per-issue forecasting and relative sorting is a pretty important piece of someone’s overall planning, problem-solving, and execution of tasks. In fact I know it is because these elements are core to problem-solving. And between-issue sorting could be a more tangible and specific measure of a developer's judgment. Arguably, good planning about tackling an issue is also a measure that relates to productivity.
Moving on from this, you could say, problem-solving goes into productivity, but it’s not productivity (I frequently argue in my talks and papers that it is useful for organizations and leaders to focus more on the former than the latter). Still, connecting increases in “time savings” to “productivity,” is an extremely contentious exercise and has been since about the time we started talking about factories. Given reactions in software circles to “productivity” generalizations, I’m surprised this doesn’t get more explanation in the study. The main thing I will say here is that it’s pretty widely acknowledged that measuring a simple time change isn’t the same as measuring productivity. One obvious issue is that you can do things quickly and badly, in a way where the cost doesn't become apparent for a while. Actually, that is itself often a criticism of how developers might use AI! So perhaps AI slowing developers down is a positive finding!
We can argue about this, and the study doesn't answer it, because there is very little motivating literature review here that tells us exactly why we should think that AI will speedup or slowdown one way or another in terms of the human problem-solving involved, although there is a lot about previous mixed findings about whether AI does this. I don’t expect software-focused teams to focus much on cognitive science or learning science, but I do find it a bit odd to report an estimation inaccuracy effect and not cite any literature about things like the planning fallacy, or even much about estimation of software tasks, itself a fairly common topic of software research.
Nevertheless, I suppose the naturalistic setting of the tasks means that “finishing an issue” has some built-in developer judgment in it that the issue was finished well. To their credit, the study thinks about this as well, encouraging developers to sincerely finish their issues, and they know they're being recorded. So I'm not really concerned that people are doing something other than sincere working in this study.
If we are interested in learning about what corrects the perceptions of developers about the time it takes to complete an issue, I would like to know more about how developers triage and assess issues before they start to do them. That is not necessarily “productivity,” but metacognition.
Time estimation as a human cognitive task. This might seem like a small quibble – but the post-task time estimate is not the same operationalization as the pre-time per issue estimate, and as an experimentalist that really grinds my gears. We think very carefully and hard about using the same operationalizations for things, and asking participants to make exactly the same judgment or do the same responding in a repeated-measures design. Their design has developers estimate the time for each issue with and without AI, but then at the end, estimate an average of how much time AI “saved them.” Asking people to summarize an average over their entire experience feels murkier than asking them to immediately rate the “times savings” of the AI after each task, plus you'd avoid many of the memory contamination effects you might worry about from asking people to summarize their hindsight across many experiences, where presumably you could get things like recency bias, with people’s overall estimate of “AI time savings” being impacted more by the last task that they just did. I’m not sure why you would do it the way it’s done in this study.
I have another social-psych-feeling question about this study design which is whether asking people to estimate the time-savings of a task twice with the only differentiator being “now imagine doing it with AI” feels like a leading question for people. People like patterns. If you ask someone to make two different estimates and change one thing about the one estimate you’re pretty much encouraging them to change their guess. Of course that doesn’t explain the optimism bias, which I think could certainly be real, but I’m just pointing out that it’s not a given that we’re eliciting “deep beliefs about AI” here.
I wonder if social desirability plays a role. People are always anxious to not be wrong about their guesses in studies. The instructions to participants even emphasize: “we expect you might personally find it useful to know if AI actually speeds you up!” and the study is named “METR Human Uplift Pilot,” all of which any reasonable participant might read and think, “this study is about AI speeding developers up, so it probably sped me up.” I have learned working as a psychologist with software teams that people will believe a frightening number of things you say just because you have a PhD, and it’s worth being careful about accidentally conveying researcher motivations in the messages participants are hearing. In fact, the advertisement also says “the study aims to measure speedup”!
They also mention that to incentivize accuracy within the experiment, they pay for more correct point estimates, which is an interesting choice and also possibly a confound here if you're getting the message that the study is about "speedup." The evidence for whether monetary incentives increase accuracy is mixed. Hard to say what this does in this case, but I think we can ask whether this post-work estimation is a comprehensive measure of developers' persistent, robust beliefs about AI.
Order effects.
Because developers can choose how they work on issues and even work on them together, this study may inadvertently have order effects. Consider this: when you sit down to work on issues, do you work completely randomly? Probably if you’re like most people, you don't. You may have a sense of pacing yourself. Maybe you like to cluster all your easy issues first, maybe you want to work up to the big ones. The fact that developers get to choose this freely means that the study cannot control for possible order effects that developer choice introduces. Order effects can certainly impact how we work.
Possible order effects can troublingly introduce something that we call “spillover effects” in RCT-land. This happens classically when information from one condition is shared to the other condition, and so treatment can impact the supposed “non-treatment” observation. We could also call this contamination, or interference – I like to use the term contamination for the visceral accuracy. Suppose that working with AI has an effect that lingers after the task is done, like a developer is reading their own code differently or prioritizes a different task within the issue. Suppose that one condition is more tiring than the other, leading the task immediately following to be penalized. In text they say "nearly all quantiles of observed implementation time see AI-allowed issues taking longer" but Figure 5 sure visually looks like there's some kind of relationship (Figure 5) between how long an issue takes and whether or not we see a divergence between AI condition and not-AI condition. That could be contained in an order effect: as will get tiring by the end of this piece I'm going to suggests that task context is changing what happens in the AI condition.
As uncovered by the order effects here, there is also a tremendous amount of possible contamination here from the participants’ choices about both how to use the AI and how to approach their real-world problem-solving. That to me makes this much more in the realm of a “field study” than an RCT. Well-informed folks have reasonable disagreements about this; Stephen Wild for instance points out that a within-person RCT is a reasonable descriptor. I don’t land on the side of feeling comfortable calling this an RCT in the context of what we are specifically trying to test here (and because it annoys me when studies use medical research language to confer authority to their claims over and above other methods, which is strongly suggested in the intro). I personally think that the term RCT is implying you have a very strong argument for the “controlled trial” part of the design in the context of the contamination that’s reasonable to expect. Ben Recht’s writeup lands on my side: “First, I don’t like calling this study an “RCT.” There is no control group! There are 16 people and they receive both treatments. We’re supposed to believe that the “treated units” here are the coding assignments.”
Really, the critical issue I and others keep coming back to is that in this study design, we can never observe the same task solved by AI and not being solved with AI. There is a lot of information contained within these developers’ heads about these issues, presumably a project history, and their own metacognitive strategies about how they’re problem-solving. This isn’t purely a look at the treatment effect of AI usage.
It’s worth noting that samples of developers' work are also nested by repository. Repositories are not equally represented or sampled in this study either; while each repo has AI/not AI conditions, they’re not each putting the same number of observations into the collective time pots. Some repositories have many tasks, some as few as 1 in each condition. Repositories and their nature and structure were something of a causal ghost for me in this study. Given that the existing repo might very steeply change how useful an AI can be, that feels like another important qualifier to these time effects being attributed solely to the AI, rather than estimates that should be disaggregated down to developer * AI * issue * repository interactions.
Developer differences & who these developers are
I thought it was striking that developers in this study had relatively low experience with Cursor. The study presents this in a weirdly generalized way as if this is a census fact (but I assume it’s about their participants): “Developers have a range of experience using AI tools: 93% have prior experience with tools like ChatGPT, but only 44% have experience using Cursor.” They provide some minimal Cursor usage check, but they don’t enforce which “AI” developers use. Right away, that feels like a massive muddle to the estimates. If some developers are chatting with chatgpt and others are zooming around with Cursor in a very different way, are we really ensuring that we’re gathering the same kind of “usage”?
I think a different interesting study would have been testing the effect of training people in a structured and comparable way to use a single AI tool, with an informed set of learning goals, and testing a pre- and post- about how they tackle the same issues, where we control the order effects as well. Particularly because we know that effects like pretesting can change how well people solve problems with the assistance of technology – your metacognition about how you are solving a problem can have a huge impact on your problem-solving.
The study does not report demographic characteristics nor speak to the diversity of their sample beyond developer experience. This isn’t uncommon for software work, but I don’t like it. I do not mind case studies and small samples, I think they are often very necessary. But if you’re studying people and making claims about how all developers work I think you should include large social demographic categories that robustly and constantly impact the experiences of people in tech. This potentially also matters in the context of the perceptions developers have about AI. In my observational survey study on AI Skill Threat in 2023, we also saw some big differences in the trust in the quality of AI output by demographic groups, differences which have continually come up when people start to include those variables.
Who we’re learning from also matters because the claim of the study is that this is interested in the effect of AI on productivity in general. The study cautions its limitations throughout the end sections, but what we think is a representative sample of "developers" (both current state in terms of the industry now, but also with an eye toward important goals like including underrepresented perspectives, because the industry of the future looks different) is an important thing to get clearer about. Jordan Nafa points out that ideally you would want to think about a rich pre-survey that clearly gauges experience participants have using AI coding tools, and I would say even more specifically that we could consider designs which identify specific skills and attempt to do a skills inventory or audit. Every study cannot contain everything, but these would be ways to include different sorts of important information into our model and could possibly provide important validity checks.
What type of effect should we even be expecting?
Continuing with our research design hats on, I want you to ask a few more questions of this research design. One big question that occurs to me is whether group averages are truly informative when it comes to times savings on development tasks. Would we expect to see a single average lift, across all people, or a more complex effect where some developers gain, and some lose? Would we expect that lift to peter out, to have a ceiling? To have certain preconditions necessary to unlock the lift? All of this can help us think about what study we would design to answer this question.
The idea that whether or not we get “value” from AI changes a lot depending on what we are working on and who we are when we show up to the tools, is something much of my tech community pointed out when I posted about this study on bluesky. Here’s a reply by David Andersen:
This is very much my experience also. I've had Claude write a bunch of html+JavaScript UI stuff for me that's totally out of my normal practice and it's been fantastic. It is anti-useful for more than autocomplete in research code in my domain (though great for quick graphing scripts).
It’s worth noting again that developers’ previous experience with Cursor wasn’t well controlled in this study. We’re not matching slowdown estimates to any kind of learning background with these tools.
Reactions to this study: get good at recognizing the bullshit
Thus far, we’ve been taking a scientific walk through this study in the hopes that it’s an interesting aid to thinking about research methods. But let’s be real, few people in this industry are taking findings direct from the appendices of a study, unless you are in the know and signed up for this newsletter.
To the extent that the news talks about developers at all, it usually wants a dramatic story. Let’s look at how three different pieces of news media describe these findings, ranging from misleading to flat wrong to good. I googled “AI slows down developers” and pulled a few takes.
Reuters: “Contrary to popular belief, using cutting-edge artificial intelligence tools slowed down experienced software developers when they were working in codebases familiar to them, rather than supercharging their work, a new study found.” and "The slowdown stemmed from developers needing to spend time going over and correcting what the AI models suggested."
While not factually inaccurate, it’s pretty misleading if you don't read the study. I don’t know why journalists always feel the need to call every piece of science they report on “in-depth,” but it implies that vast amounts of developers were studied. While it’s accurate to say these folks were working on codebases familiar to them, it completely skips by the suggestive evidence in the study that people find AI less helpful with their expertise/familiar areas and more helpful with more novel problems. It very confidently asserts that we KNOW why the slowdown happens (the study itself caveats this). It also ignores what I’m going to talk about next – the times this slowdown apparently vanishes.
Techradar has an article with the subheader: “Experienced developers aren't getting any benefit from AI, report claims,” which is more squarely in the realm of absolutely wrong about what the study even says. There are literal quotes from developers talking about benefits!
Techcrunch, on the other hand, has an article that felt more balanced to me. They give high-level study details, and even emphasize information about the participants that contextualizes the evidence and how we should generalize about it for our own lives – e.g., “Notably, only 56% of the developers in the study had experience using Cursor, the main AI tool offered in the study.” They use language like “[these] findings raise questions about the supposed universal productivity gains,” which I think is a very fair description, and keep their prescriptive take to the sensible “developers shouldn’t assume that AI coding tools [...] will immediately speed up their workflows.”
I am entirely of the mindset that leaders are the ones who need to be told this, but fair enough.
I’ve been reading Calling Bullshit by Carl Bergstrom and Jevin West, and I recommend their chapter on causality for its relentless, but fun useful breakdown of how evidence gets mistranslated across headlines and social media and even by experts and scientists.
Overall Impressions
I think the most admirable and impressive part of this study is getting the least amount of credit in the press on it: their recruiting and the real-world setting. It’s difficult to motivate people to participate in research that takes a lot of effort and time, and choosing to recruit among a specialized population like open source maintainers, working in the context of their own projects, sets the bar even higher. This is an interesting population and setting to study. I don't disagree with the push in the intro that many "AI benchmarks" kind of studies are artificially constrained. I just think we have a lot of behavioral science questions before we can be confident about this kind of estimate.
I suspect that the high bar for this kind of recruiting (and the sheer amount of time it takes to monitor people working through many tasks) is a piece of the small sample size (in terms of individual people – the task is somewhat the unit of focus in the study, and the tasks are a good collection). This is also a reason that I feel more kindly about the small sample size than many of the people who texted me this study. We often internalize the idea that small sample = bad. This really isn’t true, and it’s dangerous to apply as a generalization. We’ve observed dazzlingly important mechanisms in biology based on small samples. It all depends on your experimental question.
However, you aren’t wrong if you had the instinct to ask how this limits us, because it limits us in precisely the way that the press and social media posts about this study aren’t taking into account. We want a large number of people if we’re going to make a generalization about developers as a group, not just within-developer effects. For instance, we want to consider whether we’ve done a good enough job of a) powering our study to show a population level effect b) including enough people, in some principled way, that we feel relatively certain our treatment effect isn’t going to be contaminated by unmeasured confounds about the people. Randomization of the treatment between people, in many cases, is better suited to handle those confounding questions, although no study design is perfect.
But beyond that, the blowup about “slowdown from AI” isn’t warranted by the strength of this evidence. The biggest problem I keep coming back to when trying to think about whether to trust this “slowdown” estimate is the fact that “tasks” are so wildly variable in software work, and that the time we spend solving them is wildly variable. This can make simple averages – including group averages – very misleading. We have argued as much in our paper on Cycle Time. In that study, cycle time is roughly analogous to gathering up a bunch of “issues” and looking at the length from start to finish. We observed over a large number of developers (11k+) and observations (55k+), and our paper describes many, many issues with issues – for instance, we acknowledge that we don’t have a huge amount of context about team practices in using tickets or the context that would let us better divide up our “cycle times” into types of work. Nevertheless, we describe some important things that run counter to the industry’s stereotypes. For instance, that even within-developer, a software developer’s own past average “time on task” isn’t a very good predictor of their future times. Software work is highly variable, and that variability does not always reflect an individual difference in the person or the way they’re working.
I am not convinced that saving time is the only thing on developers’ minds. Just like teachers, they may be asking more about what they do with their time.
The fact that this slowdown difference vanishes once we layer in sorting tasks by whether they include ‘scope creep’ speaks to the fragility of this. Take a look at Figure 7 in the appendix: “low prior task exposure” overlaps with zero, as does “high external resource needs.” This is potentially one of the most interesting elements of the study, tucked away in the back and only collected for “the latter half of issues completed in the study.” This seems to me like a good idea that came late in the game here, an attempt to begin to slice away at that task heterogeneity. Setting aside the order effects and randomization design, this could have been a better plot choice to lead with, and I personally would’ve turned those “overlapping with zero” categories a neutral color, rather than keeping them red. Point estimates are almost certainly not some kind of ground truth with these small groups. I suspect that getting more context about tasks would further trouble this “slowdown effect.”
Let’s keep in mind that the headline, intro, and title framing of this paper is that it’s finding out what AI does to developers’ work. This is a causal claim. Is it correct to say we can claim that AI and AI alone is causing the slowdown, if we have evidence that type of task is part of the picture?
We could fall down other rabbit holes for things that trouble that task-group-average effect that is at the top of the paper, as in Figure 9, or Figure 17.
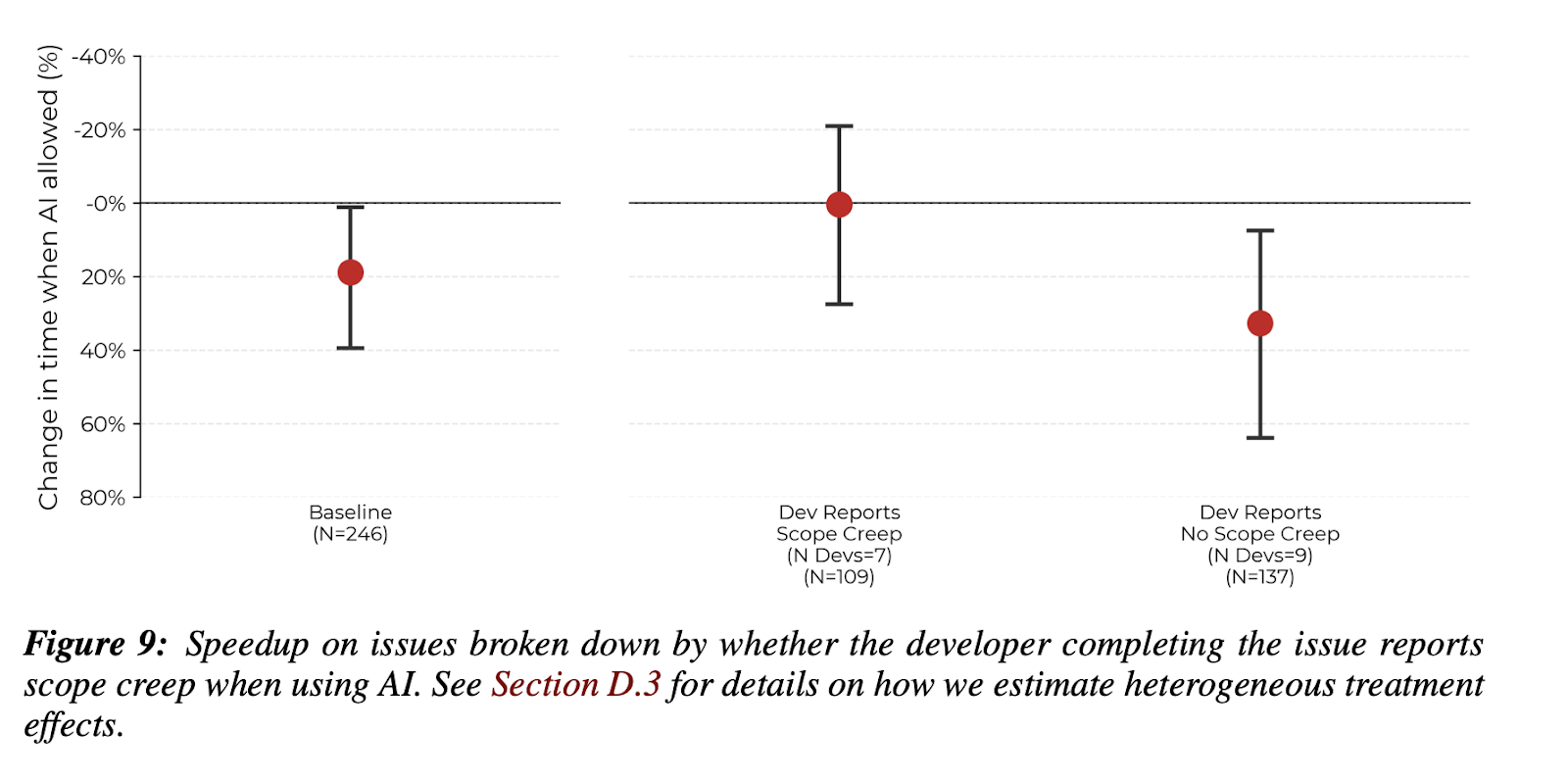
Unfortunately, as they note in 3.3., “we are not powered for statistically significant multiple comparisons when subsetting our data. This analysis is intended to provide speculative, suggestive evidence about the mechanisms behind slowdown.” Well, “speculative suggestive evidence” isn’t exactly what’s implied by naming a study the impact of AI on productivity and claiming a single element of randomization makes something an RCT. Despite the randomization, for practical and accurate purposes given what people imagine when they hear “RCT,” I land on the side of calling this a field study. As with most questions about empirical evidence, confusion and contrasting experiences with AI likely mean that we haven’t specified our questions enough.
Some clues to this are hidden in the most interesting parts of the study – the developers’ qualitative comments. There, the rich heterogeneity and strategic problem-solving developers go through as they think about interacting with both problems and tools is more obvious. This developer * tool * task interaction (which can be exploded further into developer * community of practice * tool * task * future tasks they’re imagining that task relying on….software is hard work!) is very difficult to study. This is one reason that when we find associations in the world, we need to hold a balance between letting them form our hypotheses but also interrogating other causes that could exist and explain this same pattern.

This certainly sounds like people are finding AI useful as a learning tool when our questions connect to some kinds of knowledge gaps, and also when the repo and issue solution space provide a structure in which the AI can be an aid. And what do we know about learning and exploration around knowledge gaps….? That it takes systematically more time than a rote task. I wonder if we looked within the “AI-assigned” tasks and sorted them by how much the developer was challenging themselves to learn something new, would this prove to be associated with the slowdown?
Other qualitative comments continue to speak to the task context, as it interacts with the AI, further showing us that this is not just measuring a “clean” effect of AI. Developers also presumably bring this thinking into their choices about how much they are using AI or not for a given issue in the “you can use AI as much as you want” condition. To quote him again, as Ben Recht noted in his piece on this study, the SUTVA does not necessarily hold (SUTVA stands for Stable Unit Treatment Value Assumption and it is a critical piece of the research design we rely on when we are thinking about RCTs for things like the effect of a drug on disease progression or outcome).
I think that entire last paragraph in the section screenshot (it's in C.1.2.) probably should’ve been in the intro to this paper. Actually, I think studying why experienced developers choose to use AI for a certain task, and when they don’t, and whether they think they get that wrong sometimes would probably be more interesting to me than time differences. That is an evaluation perspective that I wish this “evaluation of AI” world would consider, a behavioral science perspective on how developers plan and triage. It is not surprising that people are fairly bad at estimating the time future tasks will take, which is called the planning fallacy, and it is also not surprising that people relatively unused to a new tool will have an optimistic impression about it. But I don’t know anyone who actually works with human behavioral data who would ever try to use developers’ self-reports about something like time as if it were an objective systems measure. Maybe the idea that self-report and human perception has strengths and weaknesses is a big surprise for some people out there, but not for those of us who study bias in people’s perceptions of the world.
Concluding thoughts
Calling something an RCT doesn’t mean that the measures in the study are being made at the level of precision or accuracy that we might need to inform certain questions. In many takes, this study is being framed as causal evidence about the impact of AI on productivity. I deeply disagree that in the context of this study, the measures of time (or “slowdown”), as the authors write, “directly measure the impact of AI tools on developer productivity.” Direct is a very big claim for something that also contains treatment heterogeneity, task heterogeneity, developers’ individual choices, and other things we could think of here as spillover effects.
But even if we’re fully bought into the "slowdown" as presented in this study, I don’t find it particularly alarming. Working with AI is different from working without it and it’s only the people who have a massive conviction that all work with AI will be immediately cheetah-speed who might feel amazed by this. I didn’t have that preconception, and I think workflow change is hard, but I also don’t feel like the “19%” measure in this study is going to turn out to be terribly reliable.
At the end of the day I believe the most important and interesting questions about developers tools are going to be about people's problem-solving and how that interacts with context. I don’t believe multivariate effects in complex human learning and human problem-solving result in simple additive relationships that show up equally for all people as long as we pick the right magic tool.
Simple group difference averages about complex work are easy bait for the popular press but almost never what we need to answer our burning questions about how we should work. Honestly, I understand why the intro reads like it does even though I disagree with it. Sometimes researchers don’t get rewarded for the most valuable parts of what they’re doing – figuring out difficult recruitment, and increasing ecological validity by focusing on real tasks. More of the Figure 7s and less of the Figure 1s can help us improve our evaluation of evidence.
We are not going to be out of the era of extremely dramatic causal claims about software developers anytime soon, so everyone who works on or around a software team should learn how to evaluate claims about developer productivity. It’s not just that understanding software developer productivity attaches to a lot of money – it’s also that controlling the narrative about software developer productivity attaches to a lot of money. Journalism already hardly knows how to talk about technology without falling into breathless stereotypes, and headlines rise and fall by how extreme their claims are. But you don’t have to get swept up in the storm. Knowing just a bit of research design is a secret weapon you can pull out to decide what you think about claims.
Member discussion